
Since Google changed the user-agent for testing tools, what we see in them may not correspond to reality at all.
To clearly demonstrate the essence of the problem, I created a page:
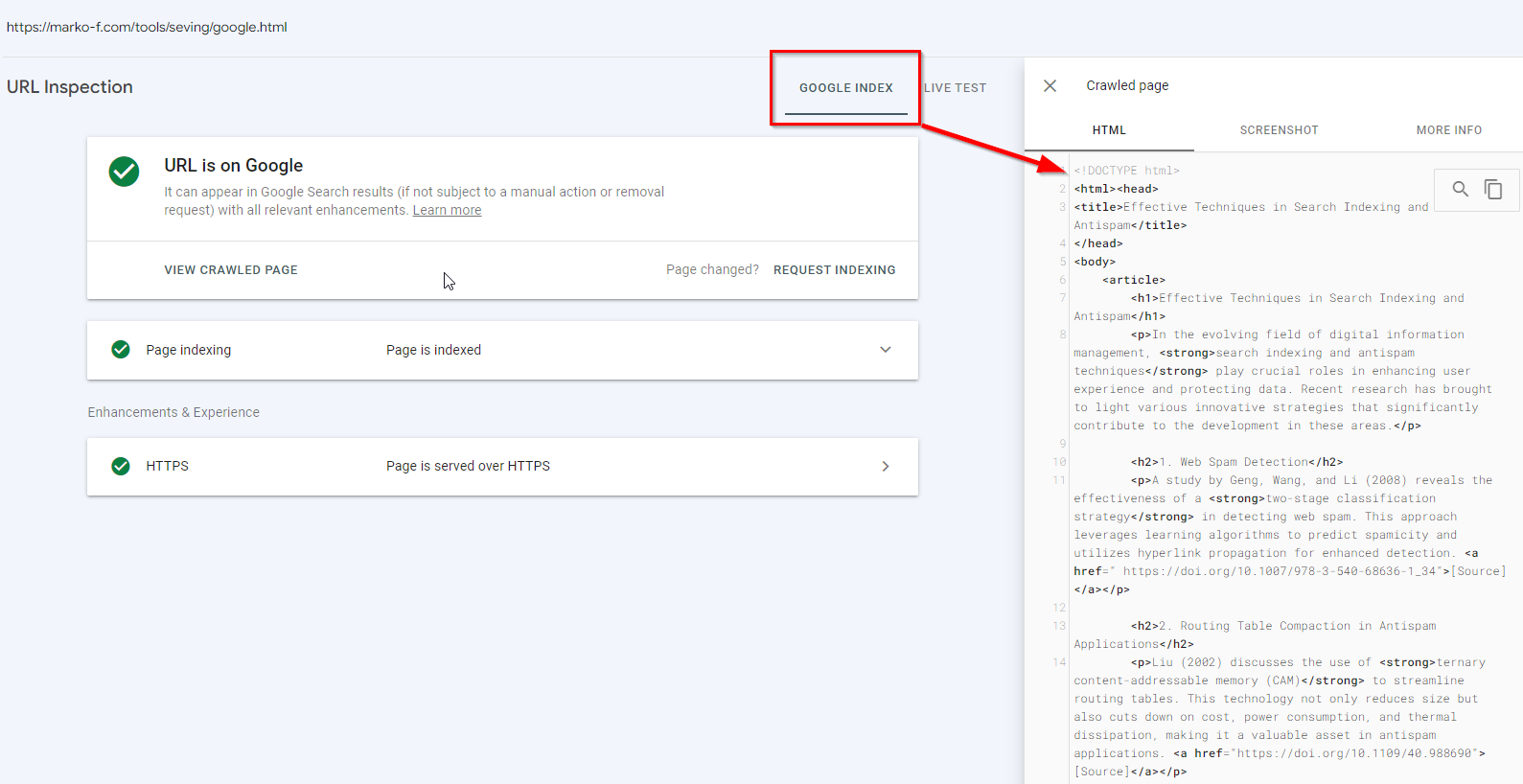
https://marko-f.com/tools/seving/google.html
When accessing this page, the HTML document that is served is:

If the request is made by Googlebot, then the content will be completely different.
The next stage of the test is checking the GSC Live Test
Let’s see what we get when we request the Live test:

Because testing tools now do not identify themselves as Googlebot, the results we get do not correspond to what Googlebot will receive.
Therefore, testing tools now require double verification to ensure there are no special server settings that deliver different code to the Googlebot user-agent compared to what a typical client receives.
How to check what Googlebot receives if there is no access to GSC?
The first idea that comes to mind is, of course, Google’s cache. Since this test page is fresh, one can look at how it is cached:

As we can see, the cached version is the one processed by Googlebot.
It should be noted that the cache stores the first available version of the HTML, which can be either raw-as fetched or rendered HTML.

At the same time, it’s important to remember that visually assessing a cached page is not advisable, as the display can be disrupted due to the same-origin policies of browsers. Therefore, while the cache can provide us with some informative data, we do not have a guarantee of its validity and timeliness. And of course, if the site we want to look at has
<META NAME=”ROBOTS” CONTENT=”NOARCHIVE”>
Then we won’t see anything.
Checking using an iframe
On the Screaming Frog website, there is an article with an interesting assumption by Dan Sharp on how to make a request on behalf of Googlebot. Thanks to Olesia Korobka for sharing this link. So, we continue the test by creating a page on a third-party domain, into which we pull the content of our page through an iframe.
The first problem I encountered is the indexing of this page.

So, I go to chatGPT to generate some content, with which I update the page content, and with a new url and return with a request for live testing and indexing.
Conducting a Live Test:

In this case, the result is essentially the same as when testing through GSC.
After indexing, unfortunately, we see in the screenshot that Googlebot has commented out the iframe:

However, a div block was added inside which is my content that is served only to the user-agent Googlebot.


Therefore, this method can also be considered valid for checking the processing of HTML on third-party websites.
Let’s continue testing with other options for integrating HTML into the page:
Testing integration using the object tag. For this, I create another page with new dummy content for indexing and integrate my URL for testing into it.
Result of the Live Test:

In the HTML-DOM, the code of the tested page did not integrate, but in the visual test, everything works as it should.

In the indexed version, it’s the same story.

Let’s try integration through Ajax. The browser won’t allow it due to CORS Policy, but Googlebot could hypothetically ignore this and process the JS.
Looking at the Live Test – and it’s a failure:

Moving on to the indexed code:

And we get a similar result.
Let’s try the outdated frameset and here we have a quite interesting case. The browser automatically removed it from the code:
This means it is present in the server’s response.

However, in the processed HTML, it is not present:

The situation is similar in the Live Test GSC.

Summarizing all the tests:
- Cache – retains what Googlebot has processed.
- iframe – on a page within a domain where you have access to GSC, followed by indexing of this page, also allows you to view the content served to Googlebot.
- All other testing methods currently did not yield results. I cannot assert that they are not effective, as the test was conducted quickly and I do not rule out errors on my part.