Описаний нижче метод не є єдиним вірним, але видався мені цікавим для того, щоб задокументувати.
Етап – 1 витягуємо тексти з сайту та автоматично зберігаємо в окремі документи
Для початку вискористовуємо Screming Frog + xpath в Custom Extraction для того, щоб отримати необхідний текстовий контент.
В результаті вигрузки custom extraction парсингу у вас буде приблизно такий документ:

Вигружаємо наш документ в google sheets.
Далі нам необхідно зберегти текст в окремі документи. Швидке рішення яке мені вдалось відшукати – https://zapier.com/
Реєструємось на сайті в 1 клік через Google-аканут на якому лежить наш файл. Обираємо сервіси з якими будемо працювати, в даному випадку це Google Sheets та Google Docs

Далі обираємо готове рішення
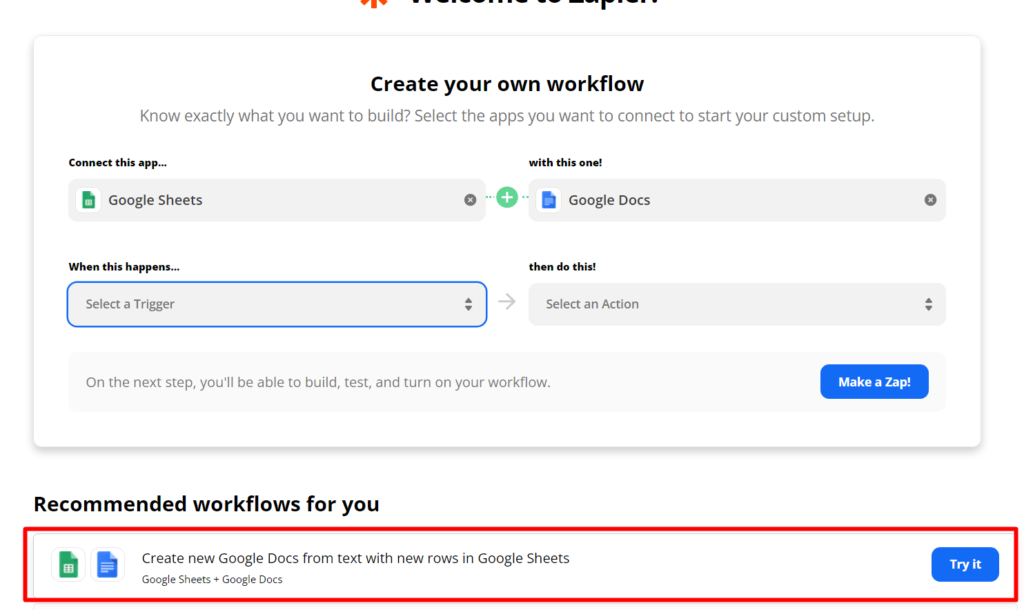
Далі проходимо всі етапи створення завдання. Тут все інтуітивно зрозуміло не будемо вдаватись в деталі.
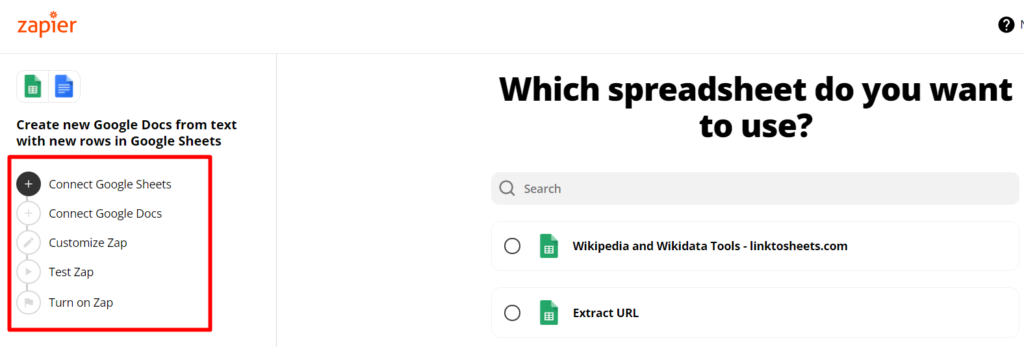
Далі в папці Transfers ми знайдеом створені нами завдання
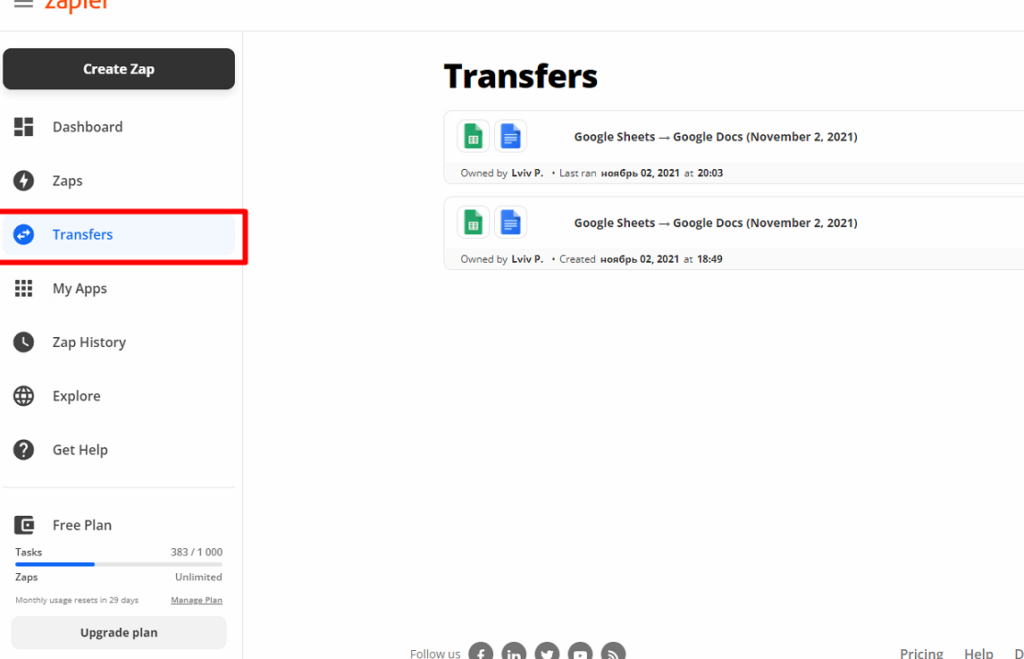
Заходимо в наше завдання і натискаємо кнопку Run

Обираємо всі екстрактори, ну або якщо у вас вибіркова вигрузка то ті які потрібні вам
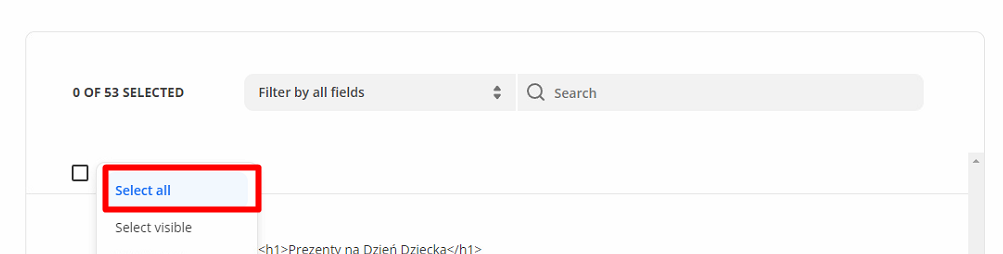
Натискаємо Next і в наступному вікні Send Data
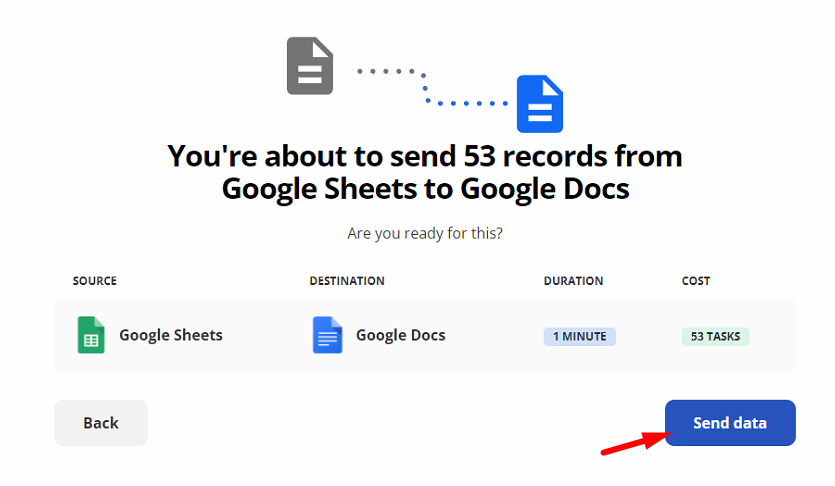
Далі, якщо натиснути View Progress побачимо процес трансферу наших текстів в окремі документи
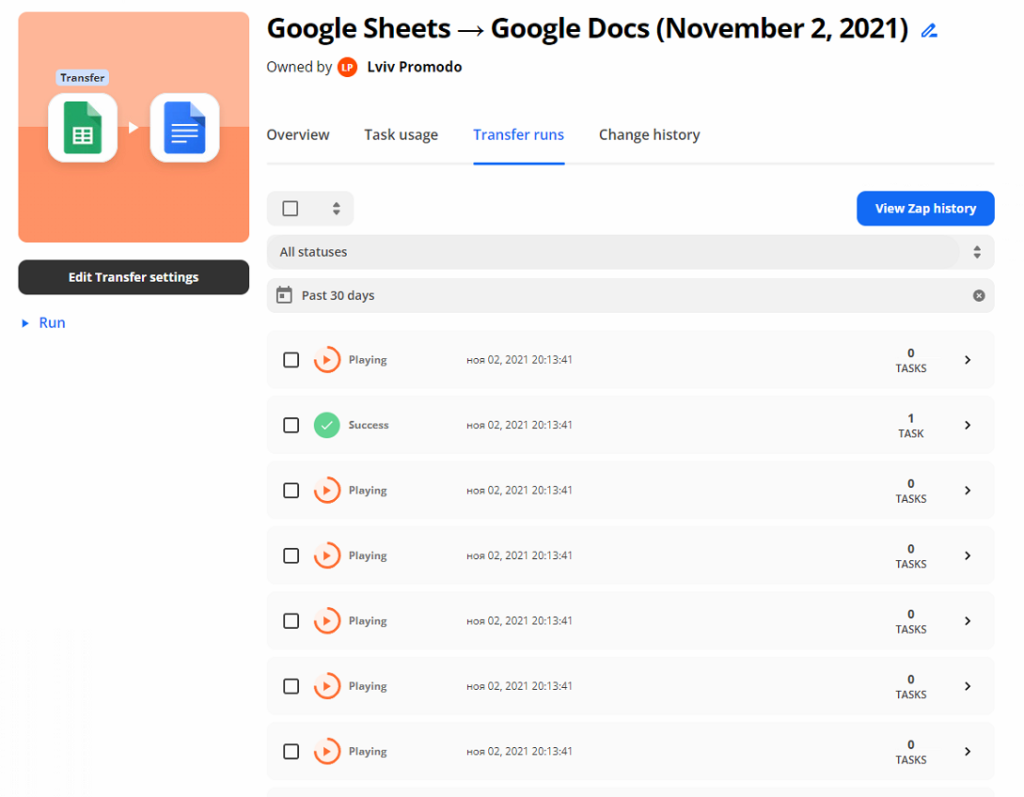
Тексти додаються автоматично в обрану нами папку. Якщо при налаштуванні проекту ви обрали генерацію назви з рядка url то відповідно й називатимуться документи

На момент написання цієї інструкції сервіс дозволяє безкоштовно виконувати до 1000 завдань на місяць.
Також якщо при переносі текстів трапилась помилка їх можна точково перезапустити.
Етап – 2 автоматична перевірка пачки текстів
Скачуємо нашу папку з текстами з гугл-диска та зберігаємо в 1 папку.
Запускаємо eTxt Antiplagiat, обираємо пакетну перевірку
Обираємо папку де лежать наші тексти, підкориговуємо налаштування під свої потреби (виключаємо домен, коригуємо пошукові системи які нам потрібні) і запускаємо.
Далі програма працює, а ми займаємось своїми справами.